What's the Difference Between Data Wrangling vs Data Cleansing vs Data Transformations

By 2025, the amount of data created, consumed, and stored is expected to exceed 180 zettabytes. For those trying to grasp this mind-boggling number, one zettabyte is expressed as 1021 (1,000,000,000,000,000,000,000 bytes), a billion terabytes, or a trillion gigabytes.
But all of this data doesn't mean a thing if it's not cleaned and shaped into usable forms.
As the amount of data rapidly increases, so does the importance of data wrangling and data cleansing. Both processes play a key role in ensuring raw data can be used for operations, analytics, insights, and inform business decisions.
The differences between the two are more subtle. By the end of this post, you'll understand how data cleaning and data wrangling are just two of several steps needed to structure and move data from one system to another. And you'll see a simple way to automate these historically manual processes without writing a line of code.
What is Data Wrangling? And Why it's Important?
Data wrangling is the process of restructuring, cleaning, and enriching raw data into a desired format for easy access and analysis. It can be a manual or automated process and is often done by a data or an engineering team.
Wrangling data is important because companies need the information they gather to be accessible and simple to use, which often means it has to be converted and mapped from one raw form into another format. This process requires several steps, including data acquisition, data transformation, data mapping, and data cleansing.
In a large organization, data wrangling is part of managing massive datasets. An entire team may be responsible for wrangling, organizing, and transforming data so it can be used by internal or external teams. Small organizations may dedicate a data scientist, an engineer, or an analyst to the task, especially if the company isn't using an automated data wrangling tool.

The goal of data wrangling is to prepare data so it can be easily accessed and effectively used for analysis. Think about it like organizing a set of Legos before you start building your masterpiece. You want to gather all of the pieces, take out any extras, find the missing ones, and group pieces by section. All of this organization makes it easier to create the project you're working on. (In this case, building a data pipeline).
But throughout the wrangling process, it's important to ensure the data is accurate.
What is Data Cleaning? And Why it's Important?
Data cleansing, or data cleaning, is the process of prepping data for analysis by amending or removing incorrect, corrupted, improperly formatted, duplicated, irrelevant, or incomplete data within a dataset. It's one part of the entire data wrangling process.
While the methods of data cleansing depend on the problem or data type, the ultimate goal is to remove or correct dirty data. This includes removing irrelevant information, eliminating duplicate data, correcting syntax errors, fixing typos, filling in missing values, or fixing structural errors.
Finding and correcting dirty data is a crucial step in building a data pipeline. That's because inconsistencies decrease the validity of the dataset and introduce the chance of complications down the line.

Let's say you're an eCommerce company that wants to set up a custom email campaign for customers. You need to pull data from your product catalog, customer profiles, and inventory to recommend the best products for each person. If you're using dirty data, it won't be easy to automatically pull data for your campaign. Differences in product formatting, misspellings of name or email addresses, and inventory information can make it difficult to populate the data. This means your team has to manually sort through and clean data to ensure it's accurate, increasing the time and effort needed for the campaign—and, ultimately, reducing the revenue.
Not only does dirty data use up your team's time, but it also decreases the credibility of your data. If you're constantly recommending the wrong products to people or sending them duplicate emails, you're going to lose customers.
To keep customers (and datasets) happy, it's important to have clean and usable data in order to get accurate insights for your company and customers.
Insights are only as good as the data used to discover them. Having consistent, accurate, and complete data improves analysis, but it also trickles down to other business activities. Using a clean dataset helps eliminate errors, which can decrease costs and increase the integrity of the dataset. When decision-makers use high-quality data to inform business decisions, it enhances accuracy and reduces the risk involved in high-stakes decisions.
No-Code Data Transformations: What is it and Why it's the Future of Data Cleanup
Manually wrangling and cleaning data takes a lot of work. At Osmos, we know that engineering and data teams' time are best spent on building products and analyzing data. So we created an AI-powered data transformation engine that lets you validate, clean up, and restructure your data to fit the destination schema and format, without having to write code.
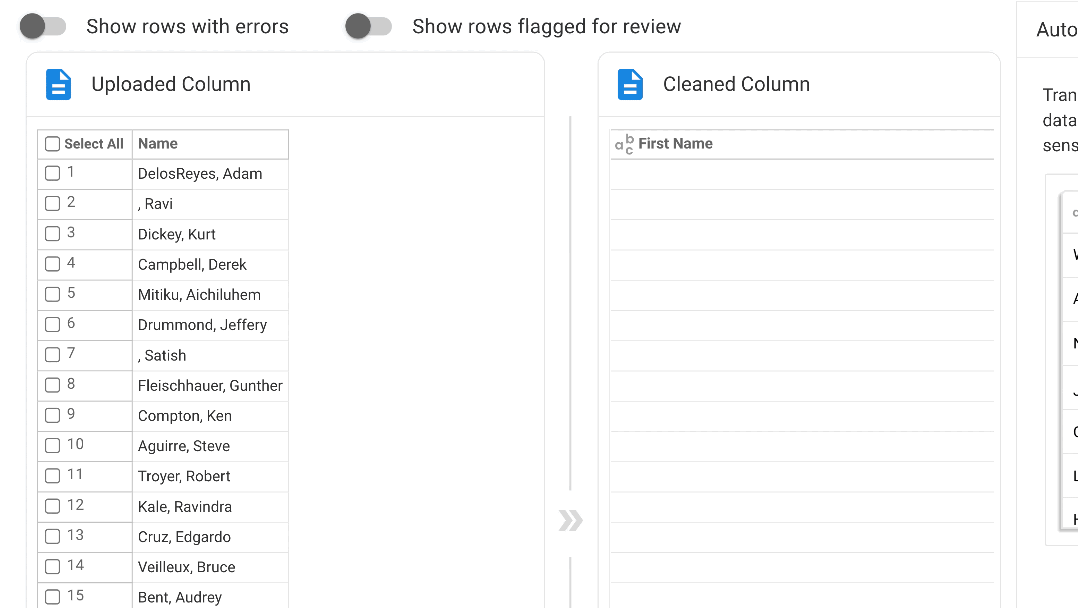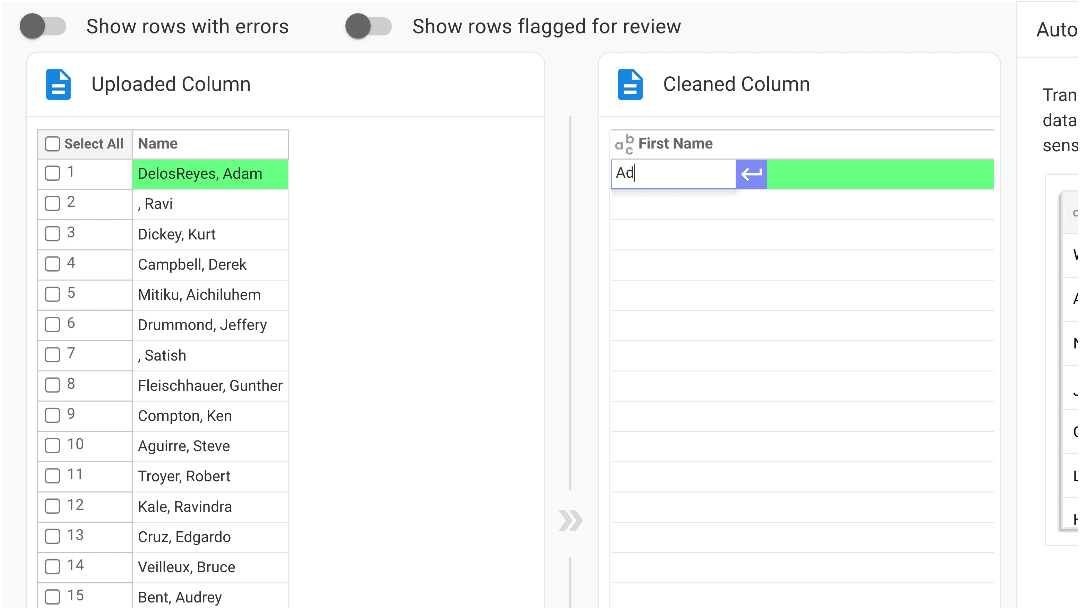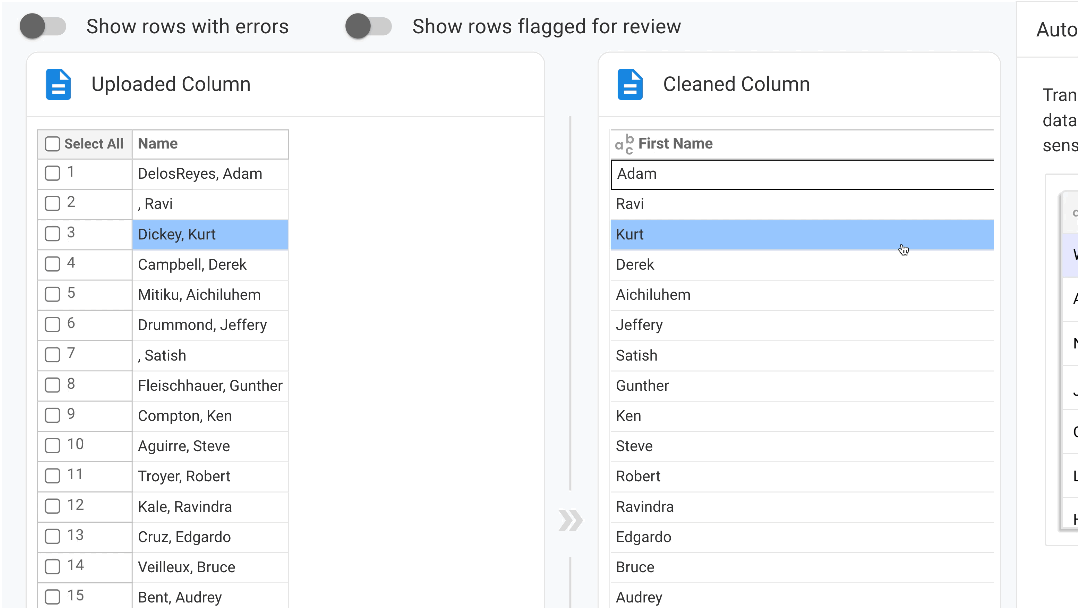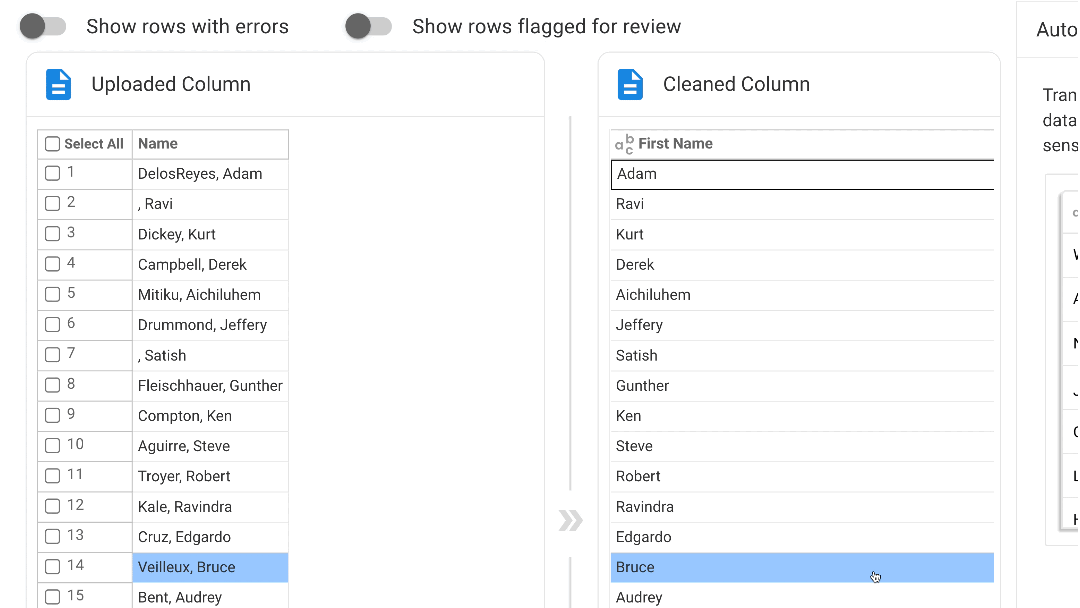
Our no-code engine has six modes to automate data clean up and transformation:
- Column mapping: Simple source to destination column mapping is useful when the source data doesn't have to be transformed or cleaned, just mapped to an output column.
- QuickFixes: One-click, data-cleanup for most common scenarios. Plus, you can combine multiple QuickFixes to cleanup your data and resolve errors.
- SmartFill: AI-powered data transformation that learns from user's examples, helping you quickly transform and map source data to the output columns. Simply providing one or two examples of the desired output teaches our AI to detect a pattern and create a program that auto-populates the remaining cells with the transformed data.
- AutoMap: Our AI automatically detects and maps columns from source to destination making it easier and faster to upload data.
- Formulas: Easy to use spreadsheet formulas let you transform and map source data to the output columns. We have formulas for date and time, math, logical, and text formulas that can be used separately or combined for complex transformations.
- AutoRecall: Our AI recalls how you previous cleaned and mapped data making each subsequent upload simpler and faster!
Osmos AI-Powered Data Transformations
Osmos AI-powered data transformations do more than save your team time. It gives your team the capacity to highlight inconsistencies, removes duplicate information, and restructure data without the need to write any code. Ingesting clean data frees up your team's time so your teams can focus on helping customers and building products.
As more organizations operate on their customer's data, the need for data wrangling and cleansing will only grow. Those using innovative no-code data transformation solutions to clean complex datasets and fix errors will be able to make the most of their data—leading to error-free data ingestion with less resources.
Should You Build or Buy a Data Importer?
But before you jump headfirst into building your own solution make sure you consider these eleven often overlooked and underestimated variables.
view the GUIDE








%201.svg)