How to Automate Data Ingestion to Unlock Business Growth

When it comes to modern businesses, there’s a continuous need to incorporate external data from customers, vendors, third-parties, and partners. Customer data ingestion is essential for a myriad of reasons including adding/removing products, updating prices/promotions, optimizing online storefronts, and being more responsive to customers.
But working with customer data is a complex process. Differences in data formats, files, sources, and systems make it difficult to seamlessly ingest data. Typically, external data ingestion takes time, effort, and technical know-how. But with innovative B2B data onboarding solutions, it's possible to automate customer data onboarding without writing a single line of code.
Let's look at why and how modern companies can automate customer data ingestion with the Osmos No-Code Data Pipelines.
What is Data Ingestion?
Data ingestion is the process of transferring data from multiple sources into a centralized data store, usually a data warehouse, where it can then be accessed and analyzed. This can be done in either a real-time stream or in batches.
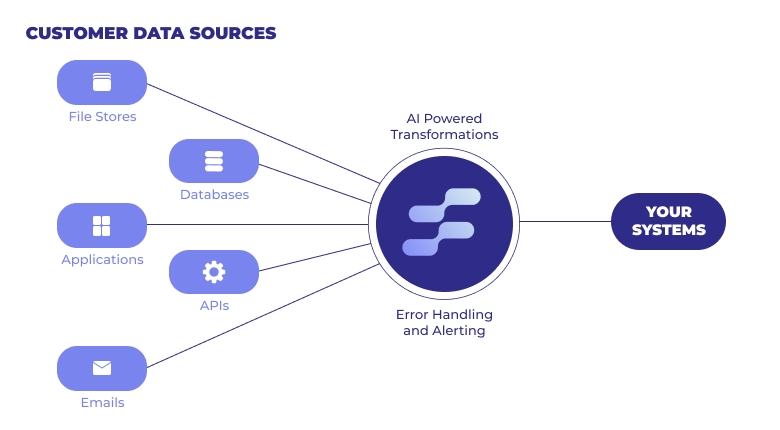
Common Customer Data Ingestion Challenges
Bringing in customer data from a variety of sources is time-consuming, manual work. Data must be wrangled, cleaned, and properly formatted for it to easily pass from one system to the next.
For example, let’s say your eCommerce company works with multiple distributors and suppliers. And you need to ingest product catalog information every day, often multiple times a day. This process is critical for you to be able to keep your product database up-to-date and forecast and plan better.
However, each distributor and supplier sends you data in a different format with some expecting to ingest via APIs, others provide nightly CSV dumps in FTPs, or they send email attachments. This approach involves a combination of manual data copy-paste and ETL tools to bring in customer data.

This is an expensive approach requiring resources from engineering and data teams to complete. Data scientists report that 45% of their time is spent loading and cleaning data. This repetitive work eats up time that can be better spent on tasks that drive business impact, such as developing models, performing analysis, or building products.
Unfortunately, eCommerce companies continue to lose profits on manual external data ingestion methods. On top of improperly allocating employees' time, Gartner estimates poor data quality costs companies an average $12.9 million per year.
However, there's a way to simplify and automate external data onboarding and unlock improvements in growth, productivity, and risk management.
Automating Data Ingestion is the Future
Onboarding customer data is now simpler with AI and no-code data ingestion solutions. Osmos automates onboarding messy, non-conformant customer data into your operational systems. Plus, you can do this with zero engineering costs and less maintenance.
Let's take a look at how an eCommerce can automate their external data onboarding from customers, vendors, and partners.
In this example, the source is product catalogue data as a CSV file located in a FTP folder and it needs to be ingested into BigQuery.

You have two separate tables joined by ProductID: one is the order details, and the second is the product details. You want to export data on the product name, quantity, and customer name.
How to Automate Data Ingestion with Osmos Pipelines
Step 1: Create a Source Connector
The first thing you have to do is build an Osmos Pipeline by starting with a connector source. Osmos lets you ingest data from various formats and sources like db, csv, etc. In this example pipeline, the source is FTP.
After selecting the source, you fill in additional information such as the connector name, host name, port number, user name, etc. With Osmos, you have access to step-by-step instructions that walk you through each item. Once you save the information, the source connector is created.
Step 2: Define a Destination Connector
Your data needs a destination. In this example, you want to ingest the product catalogue CSV file into BigQuery so you’ll create a BigQuery destination. The schema for this Connector is defined by the selected columns from the query. The schema cannot be changed after saving the Connector.
Step 3: Data Mapping and No-Code Data Transformations
You have the source and the destination. Now, it's time to map and transform the data to match the schema in BigQuery. Here is where you typically have some engineer writing code. For example, we need to map the EAN value to product ID. They would typically be writing some Python scripts to clean up the data.
With Osmos, you can validate, clean up, and restructure the data to fit the destination schema and format, without having to write code. All you do is give the system an example, and the computes and figures out what transformation is required to clean up the data. In this case, all it took was one example, and the system understood that it needed to extract the EAN value from the source.

Continue mapping the rest of the data, giving one or two examples until the system auto-populates the correct format.
Step 4: Schedule and Automate the Pipeline
With data mapping and transformations complete, you need to schedule the pipeline. You can choose the time, day, and frequency for how you want to run the pipeline. Osmos turns this one-time painful process into a repeatable, easy to solve automated solution.
Step 5: Run/Test the Pipeline
All that's left to do is run the data pipeline. Once that happens, the data is processed and appears in the destination you've selected. You can check the total number of records shared by querying BigQuery to ensure the numbers records match the number in the CSV file.
As simple as that, Osmos turned a painful product catalogue CSV cleanup and ingestion into a data pipeline that just works every day automatically.
If all looks good, congratulate yourself on finding a better way to automate your external data ingestion from customers, vendors, third-parties, and partners.
Scale and Automate Your Data Ingestion with Osmos
Using automated data ingestion solutions like Osmos to onboard external data from partners, vendors, suppliers, and customers does more than save time. It creates exponential value for your business by
- Cutting the cost of managing data
- Freeing up your engineering teams
- Getting cleaner, more accurate product catalogs
- The ability to work with more vendors to access a border set of products
The future of customer data ingestion is about letting your systems talk to your external systems, and Osmos is leading this charge. Explore how Osmos Pipelines can help your company quickly ingest data from external parties, without writing a line of code.
Go From Co-Pilot to Auto-Pilot
Discover our fully-autonomous AI Data Wrangler on Microsoft Fabric
Talk to an expert



.png)
.png)
.png)


%201.svg)