Is the Modern Data Stack the Right Solution for You?

This article will address the modern data stack from a business leader’s perspective. We will spare you lots of technical jargon and get to the heart of business challenges, namely making tooling decisions, mitigating risk, and laying a foundation for growth.
Today, nearly every leadership position oversees some degree of data management, no matter your business unit or vertical. That said, managing any amount of data is neither easy nor straightforward.
What is the Modern Data Stack?
In short, the modern data stack (MDS) is a set of technologies and tools used to collect, process, and analyze data. The key theme here being the “Analysis” of data. The tools in the modern data stack can vary from simple and easy-to-use apps to in-depth, customizable solutions designed to solve complex data situations. These apps and tools require varying degrees of expertise, and most call for engineering and developer resources to execute tasks.
The tools in the modern data stack are designed to aid in the following processes:
- Data Extraction ⟶ Retrieving from data sources
- Transforming Data ⟶ Cleaning and mapping data prior to analysis
- Loading of Data ⟶ Preparing data for storage
- Data Warehousing ⟶ Organizing and storing data in preparation for analysis
- Data Visualization ⟶ End phase, the business is left with clean, usable data
While the evolution of the data ecosystem remains in constant flux, the data management challenges that business leaders face remain constant. Organizations need to bring usable data to its destination intact and error-free. They need to make that data available to any internal team that can make use of it without silos, bottlenecks, and backlogs.
If you are interested in an in-depth analysis of the current data ecosystem as it relates to data infrastructure and data ingestion, we highly recommend our three-part series on The First Mile Problem.
Common data challenges with the modern data stack
Why data ingestion, data quality, and data transformation matter?
A recent paper from Andreessen Horowitz places data ingestion and data transformation as the foundation of the emerging data platform. They describe data ingestion, storage, processing, and transformation as the “backend” of the modern data stack, with application development as the “frontend.”
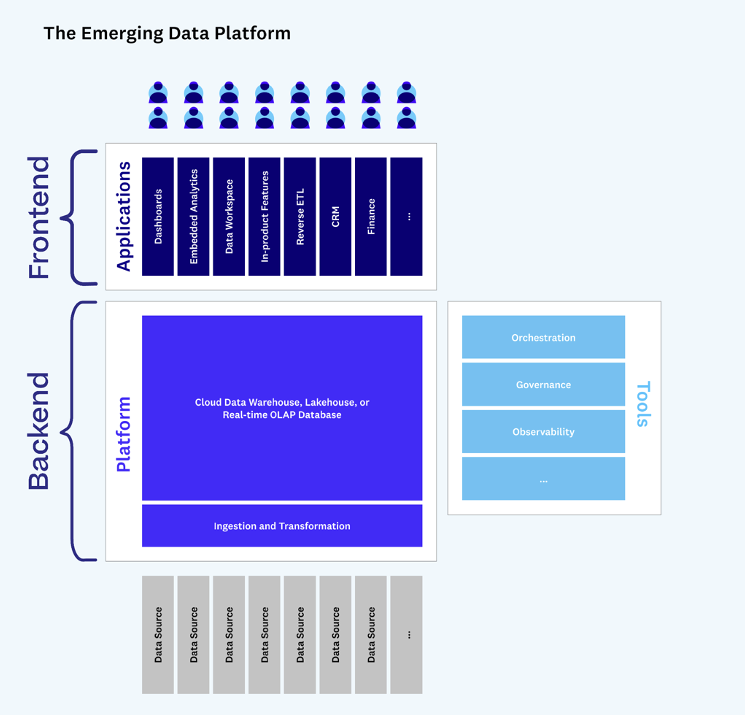
Common approaches to tackling the “backend” of the modern data stack (data ingestion, storage, processing, and transformation) are inconsistent across industries but usually fall into three categories. Businesses either throw people at the problem, resolve to use tools they’ve already invested in, or duct-tape together an in-house solution. To learn more about the pitfalls in each category, read our recent article on the pain points of customer data ingestion.
Enforcing data integrity – i.e., correcting errors, removing inconsistencies, and ensuring accuracy – is a tedious process. Let’s look at some of the common issues organizations face when putting together their data ingestion strategy.
Data cleanup is a messy process
Incoming data, especially from external parties (customers, partners, vendors), rarely arrives in the same format; if it does, there won’t be a unified structure. Mismatched schema, volume anomalies, and formatting inconsistencies are just a few of the transformation issues that present significant liabilities. Human error comes at a tremendous cost, especially in regulated industries.
Departments, from implementation to operations, are forced to contend with the challenges presented by the customer data ingestion. If they are going to make any of the data you collect useful, someone will be responsible for cleaning, mapping, transforming, and validating that data.
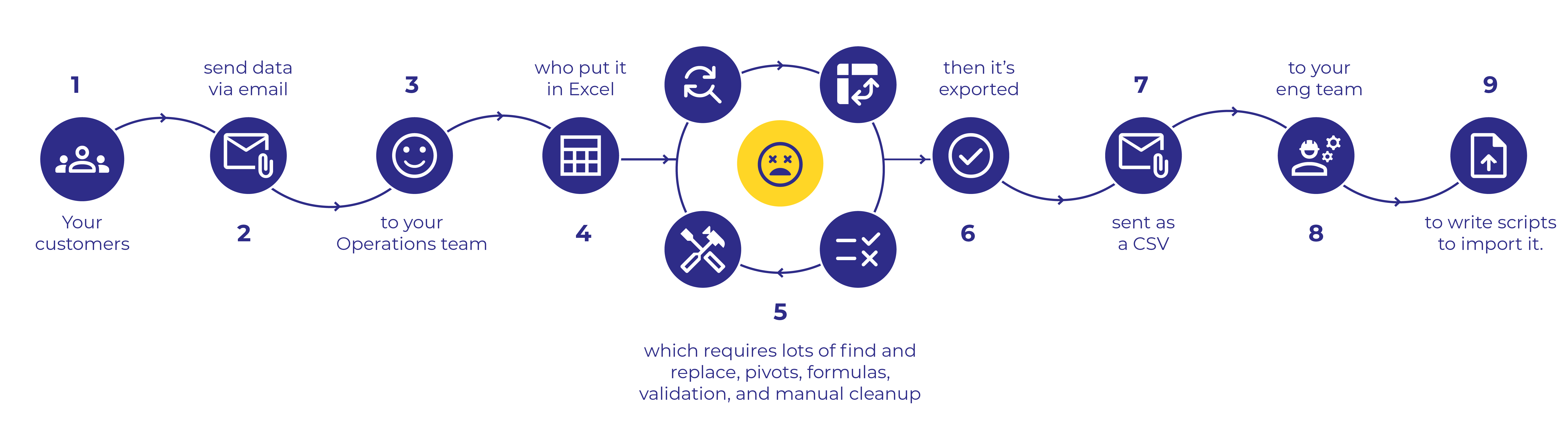
The diagram above details a scenario in which a customer-facing team collects customer data and attempts to clean it up before ushering it to the engineering team for upload.
This scenario illustrates one of the most fundamental challenges facing businesses today. The teams that understand the business value of data and need it to promote informed decision-making to accelerate business don’t have the technical skills to manipulate that data and see the process through to fruition.
Why not use tools we already have?
MDS tools like ELT (Extract Load Transform), DBT (data build tool), and Reverse ETL require SQL or Python expertise. While these tools might be scalable, relying on them to support a growing data ingestion strategy is not.
You’ve likely already invested in some MDS tools which could bring ALL of your data into the data warehouse and attempt to handle cleanup and validation there. However, using traditional MDS tools ensures you’ll perpetually rely on your engineering teams to implement all future changes, limiting your ability to scale. You’ll need an army of engineers to build, monitor, and maintain the growing number of data pipelines you create over time.
Osmos: The modern data stack for the rest of us
Osmos empowers teams in implementation and operations to get hands-on with their data and actively participate in data ingestion with powerful cleaning, mapping, and transformation functionality, regardless of technical ability.
- Move faster with fewer resources
Free your engineering and development resources to do what they do best, and leave the ETL process to us. Our fully-configurable, intuitive solution requires no prior coding knowledge, so any team can quickly start ingesting clean data on day one. - Reduce data complexities without technical resources
Discover user-friendly tools engineered to ingest and import billions of records, handle multiple data scenarios, and large file sizes. Osmos Pipelines and Osmos Uploader allow your teams to freely execute complex data cleanup tasks. - Experience data independence that scales
AI-powered data transformation gives your teams the freedom to own their data processes from extraction all the way to their destination.
Empower your teams to take data head-on. No coding required.
Supercharge your data operations with Osmos. Contact an expert today!
Go From Co-Pilot to Auto-Pilot
Discover our fully-autonomous AI Data Wrangler on Microsoft Fabric
Talk to an expert



.png)
.png)
.png)


%201.svg)