No-Code ETL vs Manual ETL: 7 Advantages You Need to Know
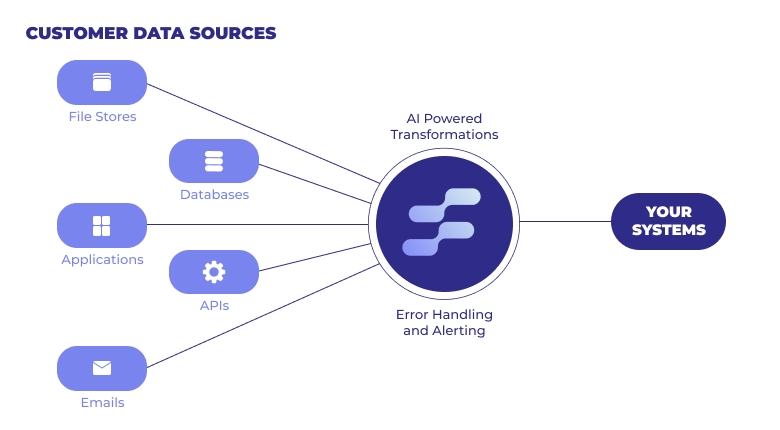
Companies today need a way to ingest vast amounts of incoming data from a growing number of sources, which traditionally falls to manual ETL pipelines. The ETL (extract, transform, and load) process is a crucial step in bringing in clean, usable data into your operational systems —especially considering that 80-90% of data that's generated is unstructured.
As the volume of data continues to rise, businesses relying on manual processes aren't able to keep up. Outdated technology, slow processes, understaffed teams, and a lack of data literacy skills prevent people from quickly accessing information.
No-code ETL data pipelines solve these issues by introducing a better, faster way of ingesting external data. Advancements in no-code tools and AI have done away with the need for manual work and bottlenecks to help companies clean, validate, and ingest data without writing a single line of code. These advancements present a myriad of benefits, such as automating workflows, reducing costs, and keeping your company competitive.
7 Benefits of No-Code ETL Pipelines
Let's look at the advantages of using no-code ETL pipelines for your business.
1. Eliminates the need for coding skills
The demand for talent with coding skills has skyrocketed within the last few years. A LinkedIn study about the most in-demand jobs shows the need for specialized engineering roles grew by 25% between 2019-2020, and data scientist roles have grown 46% since 2019.
As demand increases, so do salaries. Robert Half released its 2022 Technology Salary Guide, which reveals the average cost of employing a variety of technical experts.

A no-code ETL pipeline eliminates the need for high-cost talent spending their time manually building and maintaining data pipelines for. Now your teams can utilize pre-built connectors, APIs, and AI-powered data transformation to ingest clean data in your desired format on recurring basis.
Using a no-code ETL pipeline lets you move data with minimal IT support, as you can build complex pipelines in less than five minutes—all without extensive coding skills. Your customer-facing teams will be empowered to onboard external data without having to dive in to the details of the underlying code.
2. Easy to use
No-code ETL pipeline tools make it simple to use for non-technical users and teams. Now your customer-facing teams can develop new ETL pipelines in a matter of minutes. This makes it simpler for everyone to contribute to your data efforts, which allows engineers and developers to focus on higher-value projects, like product development and analyzing data.
For example, setting up an Osmos Pipelines only takes five minutes. Pre-built connectors let you choose where to send the source data after it's transformed. Your team can clean and restructure the data using no-code data transformations like formulas, training examples, and column mapping. Once you decide how to structure the incoming data, you can automate it by choosing how often you want the pipeline to run.
The simple process makes it possible for people without deep technical skills to build recurring data pipelines.
3. Simple to maintain
Maintaining a manual ETL pipeline means having a team with a deep understanding of programming languages. They have to know how to work with a variety of code and maintain it over time. This can become expensive, especially if you're a SaaS company that needs to ingest data from hundreds of partners and customers.
Consider an eCommerce company that wants to automate ingestion of product catalog data from multiple distributors and vendors. The engineering team would not only have to build a new data pipeline for each distributor and vendor, they would also have to maintain quality checks and validation at each stage of the process. Plus, the time and money it takes to fix broken data connections and create technical documentation.
No-code ETL pipelines are as easy to maintain as they are to set up. With built-in exception management feedback loops, you can quickly get notified, resolve errors, and maintain transformations. This saves the team's time and reduces internal roadblocks, because there's no need to manage errors, generate logs, and ensure everything is properly stored in your operational system.
4. Automate workflows
The 2021 Big Data and AI report by NewVantage Partners found that only 39% of companies are managing data as a business asset. While many businesses understand the importance of data, they struggle to make it a part of everyday work.
Efficient workflows are a key benefit of no-code ETL pipelines. Developers no longer need to manually code a separate script to run a pipeline. Instead, an no-code ETL pipeline automatically runs according to the schedule you choose. You set the time, date, and frequency—you can even do a manual run outside of the schedule, if necessary.
5. Cost saver
You absolutely need a developer to create custom ETL pipelines. And if your company handles multiple data sources, you likey need an entire team of developers. The average salary for an ETL developer in the U.S. is about $110,000, but this number can climb to over $154,000 depending on location and demand.
Using a no-code ETL pipeline drastically reduces the cost of talent. While you may need to hire developers based on your company needs, you won't have to pay for a team of developers to build, maintain, and test your ETL data pipelines.
On top of reducing talent costs, using no-code ETL pipelines can also prevent costly mistakes and maintenance. It takes time and money for data teams to fix broken data connections, add new data sources, create technical documentation, and train and onboard new users. But a no-code ETL pipeline with an intuitive interface and pre-built connectors, like the Osmos Pipeline, eliminates the need for extensive training and maintenance time.
6. Scalability
A manual ETL process is often designed to meet the current needs of a business, rather than its future needs. It can handle today's data volume and sources, but it likely won't be able to effectively scale as the volume, velocity, and sources increase.
For example, a martech company's ETL process is optimized for ingesting campaign and online data. But if it wants to leverage offline transactional data from their retail customers’ systems, the company will likely run into issues with performance and pipeline failure as it tries to bring in this data.
If your company wants to scale and stay competitive, it needs the ability to quickly add new data sources. With no-code ETL pipelines, you can quickly add data sources then transform, validate, and ingest the data to match your destination’s schema in a few minutes. This will get you a leg up on competitors.
7. Agility
Companies need to be agile to stay competitive. Rather than slowing down teams, no-code ETL pipelines can enable no-technical users to set up basic data pipelines. This flexibility and speed helps your teams move faster, ingest data quicker, free up internal resources, and make better business decisions.
No-Code ETL Pipelines for Data Ingestion Automation
As with all new technology, certain companies are skeptical of no-code ETL data pipelines. They prefer a custom, hard-coded system that relies on engineers and developers to extract the data, transform it into a usable format, and load it into the company system. This process is incredibly time-consuming, expensive, and doesn’t scale well.
To stay competitive as a business, it's time to consider no-code ETL tools like Osmos Pipelines. Not only will you reduce costs and increase your agility, but you'll empower your team with easy-to-use technology that automates workflows and simplifies data ingestion. Ultimately, no-code ETL pipelines make it easy for your entire team to get the information they need without writing complex code.
Go From Co-Pilot to Auto-Pilot
Discover our fully-autonomous AI Data Wrangler on Microsoft Fabric
Talk to an expert








%201.svg)